Text-to-Speech
von Lea Wagner und Michael Schmidbauer
Abstract
In diesem Blogbeitrag widmen wir uns dem Thema Text-to-Speech (TTS). Bei Text-to-Speech handelt es sich um eine vielseitig einsetzbare und faszinierende Technologie zur computergestützten Generierung von natürlicher und menschenähnlicher Sprache.
In dem Beitrag betrachten wir einerseits die vielfältigen Einsatzmöglichkeiten von TTS wie beispielsweise die Unterstützung von sehbehinderten Personen. Andererseits beleuchten wir den Aufbau und die Funktionsweise dieser Technologie genauer. Für die Erklärung betrachten wir die beiden Modelle Tacotron 2 und Vall-E.
Einleitung / Motivation
Die Text-to-Speech-Technologie hat, wie viele Anwendungen der Künstlichen Intelligenz, in den letzten Jahren erhebliche Fortschritte gemacht. Ihr Einfluss auf verschiedene Bereiche unseres täglichen Lebens ist beachtlich. Prominente Beispiele für ihre Anwendung wären Sprachassistenten wie beispielsweise Siri oder Alexa, aber sie waren längst nicht die ersten. Schon lange wird die TTS-Technologie beispielweise in Navigationsgeräten verwendet.
Mit Hilfe dieser Technologie wird es Maschinen ermöglicht, Text in natürliche Sprache umzuwandeln. Dabei wurde erst mit Einsatz von Künstlicher Intelligenz ein nahezu menschlicher Klang ermöglicht. Doch gibt es noch immer Stolpersteine wie beispielsweise Dialekte, die von den Systemen heute noch nicht perfekt erzeugt werden können.
Nichtsdestotrotz ist es unbestreitbar, dass die Text-to-Speech-Technologie ein wesentlicher Bestandteil der heutigen Mensch-Computer-Interaktion geworden ist. Sie erhöht die Sicherheit im Straßenverkehr oder ermöglicht es, sehbehinderten Personen besser an der zunehmend digitalen Welt teilzunehmen.
Gerade für diese Personengruppe kann die TTS-Technologie einen deutlich besseren Zugang zu digitalen Informationen ermöglichen. Mit TTS können ihnen digitale Inhalte vorgelesen werden und damit der Zugang zum digitalen Leben erleichtert werden.
Darüber hinaus bietet die Integration der Text-to-Speech-Technologie für die Unterhaltungsindustrie viele neue Möglichkeiten. Hörbücher, Podcasts, Videospiele, Filme und Serien sind einige der Einsatzgebiete, bei denen TTS-Systeme heute oder in naher Zukunft eine große Rolle spielen können. So wäre es möglich ein deutlich immersiveres Spieleerlebnis zu erzeugen oder eine Sprachfassung eines Films für eine Sprache zu generieren, bei der heutzutage der Markt zu klein wäre, um die Kosten zu rechtfertigen.
Durch die ganzen Möglichkeiten sollte man allerdings nicht außeracht lassen, welche potenziellen Gefahren diese Technologie mit sich bringen kann. Gerade mit dem Fortschreiten von Zero-Shot-Systemen, die mit nur wenigen Sekunden Audio eine Stimme nachahmen können, entsteht auch ein großes Gefährdungspotential, dass von Identitätsdiebstahl bis hin zu politischer Einflussnahme reicht.
In diesem Block werden wir und mit den technischen Grundlagen von Text-to-Speech-Systemen befassen. Außerdem werden wir zwei moderne Systeme genauer betrachten.
Stand der Forschung
In diesem Abschnitt möchten wir ein end-to-end TTS System und ein Zero-Shot TTS System vorstellen.
Tacotron 2:
Tacotron ist ein end-to-end neurales Text-to-Speech System, welches 2018 im Auftrag von Google entwickelt wurde. Es handelt sich dabei um eine Technologie, die einen Text in Sprache umwandeln kann. Systeme wie Tacotron 2 sind entscheidend für Anwendungen wie sprachgesteuerte Systeme und assistive Technologien. Tacotron 2 sollte beispielsweise in der Zukunft für die Sprachsynthese in Google Translate und Google Home verwendet werden. Aber auch für die barrierefreiheit für Sehbehinderte Menschen stellen solche Systeme eine Hilfestellung und Bereicherung der Lebensqualität dar.
Die Besonderheit von Tacotron 2 liegt in der natürlich klingenden Sprache. Viele TTS Systeme weisen Probleme bei der Betonung, Prosodie und Semantik auf. Die Beispiele von Tacotron 2 weisen eine nahezu menschlich klingende Sprachausgabe auf.
Durch die Anwendung von vielschichtigen Deep Learning Algorithmen kann das System komplexe Muster in der Sprache erfassen und so eine möglichst natürliche Sprache erzeugen.
Bei einer Bewertung menschlicher Zuhörer erzielte das System einen MOS (mean opinion score) von 4.53 verglichen mit 4.58 für professionell aufgenommene Audios. MOS bedeutet, dass eine bestimmte Anzahl von Menschen bewertet, wie gut sich die Audio anhört.
Funktionsweise von Tacotron 2:
Tacotron 2 besteht aus zwei Hauptkomponenten, nämlich einem Encoder und einem Decoder. Der Encoder wandelt eine Textsequenz in eine Hidden Feature Repräsentation um, während der Decoder basierend auf der enkodierten Sequenz Frame für Frame ein Mel Spektrogramm erstellt. Im Blockdiagramm unten ist der Encoder in blau dargestellt und der Decoder in orange.
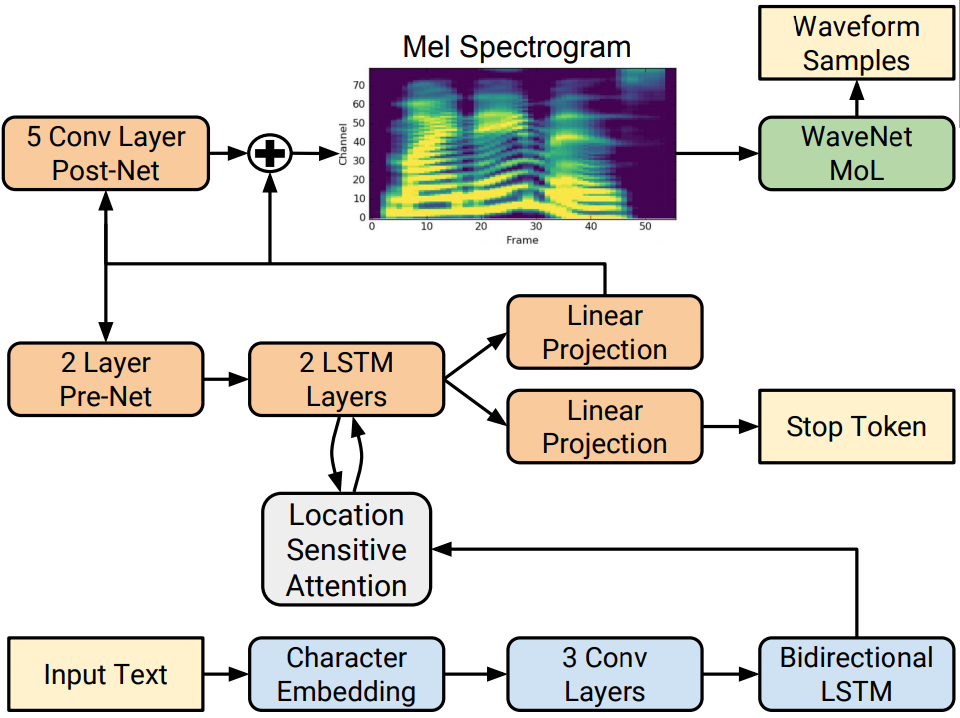
Abb. 1 https://pytorch.org/assets/images/tacotron2_diagram.png
Als Input erhält das System einen beliebigen Text. Daraus werden Character Embeddings generiert. Hier wurde zuvor ein Modell trainiert, welches jedem Buchstaben einen Vektor zuweist. In diesem Fall hat ein Vektor 512 Dimensionen, in dem die sprachlichen Eigenschaften dieses Buchstabens festgehalten werden. Diese Vektoren werden anschließend in einer Matrix zusammengefasst und an ein 3-schichtiges Convolutional Neural Network übergeben. Dieses CNN ist darauf ausgelegt, n-grams mit längerfristigem Kontext zu modellieren. Dieser Output geht dann weiter an ein bi-directional LSTM. In einem normalen LSTM wird ein Zustand zum Zeitpunkt t berechnet auf dem Input und auf dem Zustand des vorherigen Zeitpunktes t-1. In diesem LSTM werden die Daten vorwärts und rückwärts verarbeitet, wobei kontextuelle Informationen sehr gut erfasst werden können. Die Ausgabe dieses LSTM stellt die Encoder Ausgabe dar, welche jetzt high-level Informationen über die Textsequenz enthält.
Das (location sensitive) Attention Network nimmt den Output des LSTM und einen Output des Decoder Teils zum Zeitpunkt t-1, um relevante Informationen zu erhalten, mit welchen dann die Vorhersage zum Zeitpunkt t erstellt wird. Diese wird an ein 2-schichtiges LSTM übergeben. Für jeden Zeitschritt dieses LSTM wird ein Mel-Spektrogramm-Vektor vorhergesagt. Diese Ausgabe geht an eine lineare Projektion. Diese wird einmal verwendet für den Stop Token. Hier wird die Wahrscheinlichkeit berechnet, dass die Output Sequenz fertig generiert wurde. So kann das Modell dynamisch bestimmen, wann die Generierung beendet wird und ist nicht an eine feste Vorgabe von Iterationen gebunden.
Die Ausgabe der linearen Projektion geht außerdem an ein Pre-Net, welches seinen Output wieder an das 2-schichtige LSTM übergibt, um den nächsten Frame vorherzusagen. Das 5-schichtige Post-Net am Schluss berechnet einen bestimmten Restwert, welcher für ein glattes Mel Spektrogramm verantwortlich ist. Sobald alle Frames durchlaufen wurden, enthält man dann ein komplettes Mel Spektrogramm. Das Mel Spektrogramm wird dann an das WaveNet gegeben, welches als Vocoder agiert und eine Wellenform synthetisiert.
Limitationen von Tacotron 2:
Obwohl Sprachmodelle wie Tacotron 2 erstaunliche Fortschritte im Bereich der Aussprache gemacht haben, zeigen sich hier immer wieder Probleme auf. Schwierigkeiten bei der Aussprache von Wörtern mit komplexer Phonologie oder ungewöhnlicher Betonung bleiben auch bei modernen Text-to-Speech Systemen wie Tacotron 2 bestehen.
Ein weiterer Punkt ist die Generierung von Audios in Echtzeit. Da die Text-to-Speech Synthese des Systemns auf einer komplexen Architektur mit vielen Schichten beruht, ist eine Generierung in Echtzeit derzeit noch nicht möglich. Deshalb wird dieses System momentan auch nicht für die Sprachsynthese in Google Translate und Google Home benutzt.
Darüber hinaus ist es bisher nicht möglich, die Emotionen der generierten Sprache gezielt zu steuern. Obwohl Tacotron 2 in der Lage ist, natürliche Sprachausgauben zu erzeugen, fehlt die Fähigkeit, die emotionale Ausrucksweise bewusst und gezielt zu beeinflussen. Dies stellt jedoch einen eigenen Bereich der Text-to-Speech Forschung dar.
VALL-E:
VALL-E ist ein Zero-Shot TTS System, welches 2023 von Microsoft vorgestellt wurde. Das System kann basierend auf einem Text Prompt und einem Audio Prompt einen Text in Sprache mit der Stimme des Audio Prompts umwandeln. Das bedeutet, VALL-E kann Stimmen imitieren, welche nicht in den Trainingsdaten vorkommen. Auch die akustische Umgebung kann berücksichtigt werden. Wenn der Audio Prompt sich beispielsweise anhört, als würde die Stimme aus einem Telefon kommen, kann VALL-E auch das imitiere. Die Trainingsdaten stammen aus dem LibriLight Datensatz von Meta und enthalten insgesamt 60K Stunden Audio Material, welches größtenteils aus Hörbüchern stammt. Dadurch kann ein System wie VALL-E in Zukunft Anwendung in der Welt der Podcasts und Hörbücher finden.
Die Bewertung der von VALL-E generierten Audios erzielte sogar leicht bessere Ergebnisse als die Ground Truths.
Die Besonderheit des VALL-E Systems ist der extrem kurze benötigte Audio Input. Während das Vorgänger System noch einen Input von 30 Minuten benötigte, benötigt VALL-E lediglich 3 Sekunden. Durch diese erhebliche Verbesserung entsteht nicht nur eine vereinfachte Anwendung, sondern auch ein vergrößertes Missbrauchspotzenzial. Darauf wird im Abschnitt Limitationen/Ethik nochmal genauer eingegangen.
Funktionsweise von VALL-E:
Ähnlich wie Tacotron 2, nutzt VALL-E eine Encoder-Decoder-Architektur.

Abb. 2 https://www.chip.de/ii/1/2/6/7/6/9/4/0/3/3b6003cc590f29a5.jpg
Es gibt zwei Inputs, den Text Prompt und den Acoustic Prompt. Der Text Prompt wird zunächst in Phoneme und dann in entsprechende Embeddings umgewandelt. Der Audio Prompt geht an den Encoder. Hierbei handelt es sich um den Audio Codec Encoder von Facebook Research. Dieser stellt das “Arbeitstier” hinter VALL-E dar und hat nochmal einen eigenen Encoder und Decoder, wie man im Blockdiagramm erkennen kann.

Abb. 3 https://github.com/facebookresearch/encodec/raw/main/architecture.png
Der Encoder nimmt die Wellenform und führt eine Convolution durch für Downsampling. Darauffolgend wird ein LSTM genutzt für die Sequenz Modellierung. Das Ergebnis dieses Encoders ist eine kompaktere Repräsentation mit 75 beziehungsweise 100 latenten Zeitschritten im Vergleich zu 24.000 beziehungsweise 48.000 im Input. Der Decoder ist eine gespiegelte Form des Encoders, welcher wieder ein Upsampling durchführt und daraus eine Wellenform erzeugt. Dazwischen befindet sich der Quantizer.
Für diesen gibt es 8 sogenannte Codebooks. Codebooks sind Dictionaries gefüllt mit Vektoren, woraus sich 1024 Einträge ergeben. Der Input Vektor wird repräsentiert, indem er auf den ähnlichsten Vektor im Codebook gemapt wird. Diese Ähnlichkeit wird gemessen mit dem euklidischen Abstand. Dadurch gehen Informationen verloren, welche man aber gerne erhalten möchte. Mit Hilfe der Residual Vector Quantization (RVQ) wird der Restwert berechnet. Dieser wird dann auf einen weiteren Vektor im Codebook gemapt. Die finale Repräsentation ist eine Liste der Indexe, auf die die Vektoren gemapt wurden.
Sobald der Audio Codec Encoder seine Arbeit erledigt hat, wird die Repräsentation an den Decoder von VALL-E übergeben.

Abb. 4 https://miro.medium.com/v2/resize:fit:1400/format:webp/1zZmUzjNyvSa3a-b-c7bdXQ.png*
Dieser besteht aus einem Non-Auto-Regressive (NAR) und aus einem Auto-Regressive (AR) Decoder. Der AR Decoder ist dafür verantwortlich, die Input Daten des ersten Codebooks zu verarbeiten. Der NAR Decoder ist für die restlichen Codebooks verwendet. Hier wird aus diesen Repräsentationen der Codebooks die Wellenform generiert, aus der die Output Sprache entsteht.
Limitationen und Ethik von VALL-E:
Trotz der herausragenden Ergebnisse von VALL-E gibt es dennoch einige Einschränkungen, die es zu beachten gibt. Einerseits können manche Wörter unklar oder schwer verständlich sein. Darüber hinaus ist die Leistung des Systems bei Sprechern mit Akzent schlechter im Vergleich zu den Sprechern ohne Akzent. Dies liegt an den Trainingsdaten, die zu einem sehr großen Teil aus Hörbuchmaterial bestehen. Auch kann VALL-E die Emotionen der Sprache noch nicht gezielt beeinflussen. Abschließend bestehen ethische Risiken, beispielsweise im Zusammenhang mit Impersonation und Spoofing. Im Zusammenhang mit Deep Fake Videos könnten mit Hilfe von VALL-E falsche Informationen verbreitet werden. Auch könnte VALL-E genutzt werden, um beispielsweise über Telefon an sensible Daten zu gelangen.
Microsoft äußert sich zu diesen möglichen negativen Folgen in ihrem Paper. Es wird eine Möglichkeit genannt, ein System zu erstellen, welches klassifizieren kann, ob eine Audio von VALL-E generiert wurde oder nicht. Ein Solches System gibt es zum jetzigen Stand aber noch nicht.
Fazit: Tacotron 2 und VALL-E:
Trotz ihrer Unterschiede in den Systemen und Anwendungsbereichen teilen Vall-E und Tacotron 2 Gemeinsamkeiten in ihrer Architektur und Technologie. Zum einen ist das wie Verwendung einer Encoder-Decoder-Architektur, welche es ermöglicht, den Input zunächst in eine diskrete Repräsentation umzuwandeln um daraus anschließend die Sprachausgabe zu generieren. Eine weitere Gemeinsamkeit ist die Verwendung von Mel-Spektrogrammen. In Tacotron 2 wird dieses jedoch direkt als intermediäre Repräsentation verwendet, bei VALL-E aber nur im Encodec Teil. Zuletzt nutzen beide Systeme autoregressive Technologien, um die Sprachausgabe schrittweise zu generieren und so eine natürliche und flüssige Sprache zu erzuegen.
Methoden
In diesem Abschnitt geben wir einen kurzen Überblick über weitere Methoden für Text-to-Speech Systeme.
Hidden Markov Modele:
Hidden Markov Modelle (HMMs) sind eine der grundlegendsten Methoden in der Sprachverarbeitung und waren auch bei TTS-Systemen maßgeblich an der Entwicklung beteiligt. Es handelt sich um eine Methode, die statistische Eigenschaften von Sprache modelliert und die Beziehungen zwischen Text und Sprachesignal erfasst.
Das zugrunde liegende mathematische Modell eines HMMs besteht aus einer Menge von Zuständen, Übergängen zwischen den Zuständen und Emissionen, die mit den Zuständen verknüpft sind. Für die Anwendung von HMMs im Bereich der TTS-Synthese werden typischerweise drei Arten von Zuständen definiert. Die Zustände des Emissionsmodells repräsentieren die Klänge oder Phoneme, die in der Sprache vorhanden sind. Jeder Zustand ist mit einer Wahrscheinlichkeitsverteilung über die möglichen akustischen Merkmale verbunden, die für das jeweilige Phonem charakteristisch sind. Die Zustände des Übergangsmodells repräsentieren die linguistische Struktur des Textes. Sie können Worte, Silben oder andere linguistische Einheiten sein. Die Übergänge zwischen den Zuständen des Übergangsmodells modellieren die statistische Wahrscheinlichkeit, mit der eine bestimmte linguistische Einheit auf eine andere folgt. Der Anfangszustand repräsentiert den Beginn des Textes oder der Sprachsequenz. Er gibt an, welche linguistische Einheit zuerst erzeugt wird.
Die grundlegende Idee hinter HMMs besteht darin, dass der Übergang von einem Zustand zum nächsten stochastisch erfolgt, basierend auf den Übergangswahrscheinlichkeiten zwischen den Zuständen. Zusätzlich zu den Zustandsübergängen emittiert jeder Zustand eine bestimmte Wahrscheinlichkeitsverteilung über die akustischen Merkmale.
Bei der TTS-Synthese wird das HMM-Modell verwendet, um akustische Modelle zu erzeugen, die die Beziehung zwischen Text und Sprachsignalen erfassen. Der Text wird in eine Sequenz von Zuständen des Emissionsmodells übersetzt, und die HMM-Übergangswahrscheinlichkeiten werden verwendet, um die Reihenfolge und Dauer der Zustände zu bestimmen. Anhand der Wahrscheinlichkeitsverteilungen der akustischen Merkmale können dann Sprachsignale erzeugt werden, die dem Text entsprechen.
Obwohl HMMs eine bewährte Methode in der Sprachverarbeitung sind, haben sie auch ihre Einschränkungen. Insbesondere können sie Schwierigkeiten haben, komplexe linguistische Phänomene und Variabilität in den Sprachsignalen genau zu modellieren.
Deep Learning und NNs:
Deep Learning und neuronale Netzwerke verwenden mehrschichtige neuronale Netzwerke, um komplexe Funktionen zu erlernen und hochdimensionale Daten zu verarbeiten. Im Bereich der TTS-Synthese können diese verwendet werden, um direkt Text auf Sprachsignale abbilden zu können, ohne den Umweg über diskrete Zustände wie es bei Hidden Markov Modellen der Fall ist.
Eine häufig verwendete Architektur sind Recurrent Neural Networks (RNNs). Diese Modelle haben die Fähigkeit, Sequenzdaten effektiv zu modellieren und können auf den TTS-Kontext angepasst werden, um Text in akustische Merkmale zu übersetzen.
Eine Weiterentwicklung des RNN sind die sogenannten Long-Short-Term-Memory (LSTM) Architekturen. Hierbei wird das Modell mit einem Speicher ausgestattet, der es ihm ermöglicht auch über längere Abschnitte Zusammenhänge zu erkennen.
Für die Generierung des Sprachmodels wird häufig ein Convolutional Neural Network (CNN) verwendet. Diese Architektur ist besonders geeignet, um Muster in der gesprochenen Sprache zu erkennen und diese auch zu modellieren.
Transformer-basierte Modelle:
Die Transformer Technologie ist eine der modernen Architekturen im Bereich der natürlichen Sprachverarbeitung. Dabei finden sie ihre Anwendungen sowohl bei Large-Language-Modellen wie ChatGPT oder GitHubCopilot, als auch bei Text-to-Speech Systemen. So sind Transformer beispielsweise Bestandteil des oben Vorgestellten Vall-E Systems.
Im Gegensatz zu herkömmlichen end-to-end Methoden wie dem oben vorgestellten Tacotron 2 sind Transformer-basierte Ansätze effizienter und besser darin, Langzeitabhängigkeiten zu modellieren. Ebenfalls ist es möglich mit Transformer-basierten Modellen deutlich größere Datenmengen zu verarbeiten, als bei den vorhergehenden Ansätzen.
Im Vergleich zu herkömmlichen RNN-basierten Modellen haben Tranformer-basierte Modelle noch weitere Vorteile. Durch den Wegfall der rekurrenten Verbindungen ist es möglich das Training zu parallelisieren und durch die Self-Attention der Transformer kann ein globaler Kontext einer Sequenz zu jedem Ausschnitt hinzugefügt werden. Dadurch ist es möglich, längerfristigen Kontext zu modellieren.
Für eine ausführlichere Erklärung dieser Technologie verweisen wir auf den Blogbeitrag zu Large-Language-Models.
Transfer Learning:
Bei der Methode des Transfer Learnings werden Modelle auf großen allgemeinen Datensätzen trainiert, um später auf den spezifischen Anwendungsfall abgestimmt zu werden. In unserem Fall wird ein Modell beispielsweise mit Englischsprachigen Audiodateien trainiert und später auf die gewünschte Stimme angepasst.
Mit dieser Methode kann die Trainingszeit des Modells erheblich reduziert werden. Allerdings verschlechtern sich die Ergebnisse, je größer die Unterschiede zwischen den Trainingsdaten des vortrainierten Modells und des Anwendungsfalls werden.
Für genauere und umfangreichere Informationen zu diesem Thema verweisen wir auf den Blogbeitrag zu Transfer Learning.
Anwendungen
Die Anwendungsmöglichkeiten für Text-to-Speech Systeme sind vielseitig. Sie haben schon lange ihren Weg in unseren Alltag gefunden. Zu häufigen Anwendungen derartiger Systeme gehören unter anderen:
- Navigationsgeräte
- Automatische ansagen in Zügen oder an Bahnhöfen
- Sprachassistenten wie beispielsweise Siri oder Alexa
- Barrierefreiheitsfunktionen wie beispielsweise das Vorlesen dessen, was auf dem Bildschirm angezeigt wird.
- Vorlesen der Text Ein- oder Ausgabe bei Übersetzungssoftware
Beispiele für Anwendungen bei denen Text-to-Speech bereits eingesetzt wird oder ein zukünftiger Einsatz denkbar wäre:
- Nachbearbeitung von Podcasts, um einzelne Wörter zu ändern
- Aufnahme von Podcasts oder Hörbüchern
- Erstellen von Tonaufnahmen in unterschiedlichen Sprachen für Videospiele, Filme und Serien
Gerade mit dem Blick auf Zero-Shot-Systeme sollte man die Einsatzgebiete nicht außer Acht lassen, die nicht dem Wohle des Großteils der Bevölkerung dienen. Dabei werden Tonspuren oder Videos erstellt, um gezielt Personen, Unternehmen oder Ländern zu schaden. Beispielsweise, um Berichte oder Aussagen zu erstellen, die Wahlen oder den Aktienkurs in eine bestimmte Richtung drängen sollen.
Fazit
Text-to-Speech ist eine faszinierende und vielversprechende Technologie, mit großem Potential und vielseitigen Anwendungsmöglichkeiten. Die Entwicklung der letzten Jahre hat inzwischen Systeme zur Generierung nahezu natürlicher menschlicher Sprache hervorgebracht.
Die Einsatzgebiete sind dabei sehr vielseitig. Von dem Vorlesen von Texten auf dem Bildschirm für Sehbehinderte Personen, über die Unterstützung zum lernen von Sprachen, bis hin zur sicheren Verwendung von Navigationsgeräten. Darüber hinaus sind die Anwendungsmöglichkeiten in der Werbebranche, dem Kundenservice oder der Unterhaltungsindustrie nahezu grenzenlos.
Allerdings gibt es auch einige Herausforderungen im Zusammenhang mit TTS. Die Generierung von natürlichen Stimmen erfordert eine komplexe Verarbeitung von Sprache, Intonation und Betonung. Obwohl TTS-Systeme bereits erstaunlich realistische Ergebnisse erzielen können, gibt es immer noch Raum für Verbesserungen, insbesondere in Bezug auf die emotionale Ausdrucksstärke und die Anpassungsfähigkeit an unterschiedliche Textarten.
Darüber hinaus sollten ethische Aspekte bei der Entwicklung und Anwendung von TTS-Technologien berücksichtigt werden. Insbesondere der potenzielle Missbrauch von TTS für Fälschungen oder Manipulationen von Audioinhalten ist ein ernstzunehmendes Risiko. Es ist wichtig, Richtlinien und Standards zu entwickeln, um die Verbreitung von gefälschten oder irreführenden Stimmen zu verhindern und die Integrität von Audioquellen zu gewährleisten. Dabei sollte nicht außer Acht gelassen werden, dass die Risiken sowohl auf gesellschaftlicher als auch privater Ebene bestehen. Besonderes Augenmerk sollte man dabei auch auf die Zero-Shot Systeme legen.
Insgesamt bietet TTS enorme Vorteile und Chancen, aber auch Herausforderungen und ethische Überlegungen. Die weitere Forschung und Entwicklung auf diesem Gebiet sind von großer Bedeutung, um die Qualität der generierten Stimmen zu verbessern, neue Anwendungsbereiche zu erschließen und sicherzustellen, dass TTS-Technologien verantwortungsbewusst eingesetzt werden. Mit den richtigen Anstrengungen und Maßnahmen kann Text-to-Speech dazu beitragen, die Kommunikation und den Zugang zu Informationen für Menschen weltweit zu verbessern.
Weiterführendes Material
Podcast
Hier Link zum Podcast.
Talk
Hier einfach Youtube oder THD System embedden.
Demo
Hier Link zum Demo Video + Link zum GIT Repository mit dem Demo Code.
Literaturliste
-
https://ieeexplore.ieee.org/abstract/document/10057419 T. Yanagita, S. Sakti, und S. Nakamura, „Japanese Neural Incremental Text-to-Speech Synthesis Framework With an Accent Phrase Input“, IEEE Access, Bd. 11, S. 22355–22363, 2023, doi: 10.1109/ACCESS.2023.3251657.
-
https://vall-e.io/ C. Wang u. a., „Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers“. arXiv, 5. Januar 2023. Zugegriffen: 1. Mai 2023. [Online]. Verfügbar unter: http://arxiv.org/abs/2301.02111
-
https://www.researchgate.net/profile/Hazem-El-Bakry/publication/228673642_An_overview_of_text-to-speech_synthesis_techniques/links/553fa8270cf2320416eb23ed/An-overview-of-text-to-speech-synthesis-techniques.pdf M. Rashad, H. El-Bakry, R. Isma, und N. Mastorakis, „An overview of text-to-speech synthesis techniques“, International Conference on Communications and Information Technology - Proceedings, Juli 2010.
-
J. Shen u. a., „Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions“. arXiv, 15. Februar 2018. doi: 10.48550/arXiv.1712.05884.
-
„Audio samples from ‚Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions‘“. https://google.github.io/tacotron/publications/tacotron2/ (zugegriffen 4. Juli 2023).
-
„EnCodec: High Fidelity Neural Audio Compression“. Meta Research, 5. Juli 2023. Zugegriffen: 5. Juli 2023. [Online]. Verfügbar unter: https://github.com/facebookresearch/encodec
-
N. Li, S. Liu, Y. Liu, S. Zhao, M. Liu, und M. Zhou, „Neural Speech Synthesis with Transformer Network“. arXiv, 30. Januar 2019. Zugegriffen: 6. Juli 2023. [Online]. Verfügbar unter: http://arxiv.org/abs/1809.08895
-
Y. Jia u. a., „Transfer Learning from Speaker Verification to Multispeaker Text-To-Speech Synthesis“. arXiv, 2. Januar 2019. Zugegriffen: 6. Juli 2023. [Online]. Verfügbar unter: http://arxiv.org/abs/1806.04558
-
K. Tokuda, Y. Nankaku, T. Toda, H. Zen, J. Yamagishi, und K. Oura, „Speech Synthesis Based on Hidden Markov Models“, Proc. IEEE, Bd. 101, Nr. 5, S. 1234–1252, Mai 2013, doi: 10.1109/JPROC.2013.2251852.