Process Mining
von Amelie Kammerer, Joshua Groszeibl und Tabea Haas
Abstract
von Tabea Haas
In der heutigen digitalen Ära ist die Fähigkeit, Daten in wertvolle Erkenntnisse umzuwandeln, entscheidend für den Erfolg eines Unternehmens. Prozessanalyse, insbesondere durch Process Mining, ist zu einem zentralen Ansatz geworden, um Effizienz, Transparenz und Qualität in Organisationen zu verbessern. Nahfolgendes soll einen umfassenden Einblick in das Feld des Process Minings gewähren, und die verschiedenen Aspekte beleuchten, die diese aufstrebende Technologie so erfolgreich machen.
Einleitung
Heute werden wir uns mit einem faszinierenden Thema beschäftigen - Process Mining. Vielleicht haben Sie schon davon gehört, aber falls nicht, keine Sorge! Process Mining ist eine Technologie mit enormem Potenzial, die vielen noch unbekannt ist. Dabei handelt es sich um eine Methode, um Abläufe und Prozesse in Unternehmen mithilfe von Daten zu analysieren und zu visualisieren.
Stellen Sie sich vor, Sie könnten wie mit einer Röntgenaufnahme in die Abläufe eines Unternehmens blicken. Das ist genau das, was Process Mining ermöglicht. Indem es Daten aus verschiedenen Quellen wie Datenbanken oder Anwendungsprotokollen sammelt, können wir einen detaillierten Einblick in die Prozesse erhalten. Basierend auf diesen Daten wird ein Prozessmodell erstellt, das uns zeigt, wie Aktivitäten miteinander verbunden sind, wie lange sie dauern und welche Ressourcen dafür benötigt werden.
Process Mining hat eine breite Anwendungspalette und findet in verschiedenen Bereichen wie Logistik, Fertigung, Gesundheitswesen, Finanzen und Forensik Anwendung. Sogar große Unternehmen wie BMW und Siemens nutzen Process Mining, um ihre Prozessqualität zu verbessern und effizienter zu arbeiten.
Die Vorteile von Process Mining liegen auf der Hand. Durch die objektive und datenbasierte Analyse erhalten Unternehmen ein umfassendes Bild ihrer tatsächlichen Abläufe. Dadurch können Fehlerquellen, Ineffizienzen und Verbesserungspotenziale identifiziert werden. Prozesse können transparenter gestaltet und die Effizienz gesteigert werden, was letztendlich zu Kosteneinsparungen und einer höheren Kundenzufriedenheit führt.
Es gibt jedoch auch Grenzen und Herausforderungen beim Einsatz von Process Mining. Es erfordert ausreichend Daten, um aussagekräftige Analysen durchführen zu können. Zudem besteht die Gefahr, dass Unternehmen sich zu sehr in die Analyse vertiefen und zu wenig Zeit in die Umsetzung von Verbesserungsmaßnahmen investieren, was als "Analyse-Paralyse" bezeichnet wird.
In diesem Artikel werden wir Process Mining genauer betrachten, die Funktionsweise anhand einer Code Demonstration erklären, und über die Vor- und Nachteile dieser Technologie diskutieren.
Wisschenschaftlicher Blogartikel
von Amelie Kammerer
Einführung
Process-Mining wird generell als die Brücke zwischen traditioneller Prozess-Analyse und datenzentrierter Analysetechniken, wie Maschinellem Lernen und Data Mining bezeichnet. Das Ziel ist, auf Basis von Event Daten Einblicke in Prozess zu bekommen und dadurch Prozesse positiv zu verändern. Auf diese Weise bekommt man Informationen über die Prozesse, wie mehr Perspektiven für beispielsweise den zeitlichen Kontext, für die Interpretation der Daten und für das Verstehen des Prozesses.
Process-Mining kann dabei für alle möglichen Bereiche hergenommen werden, sei es Gesundheitswesen, Finanzen, Logistik oder auch bei Informations- und Kommunikationstechnologien. Bei allen Prozessen, die Event Daten liefern (s. Kapitel Event Daten).
Da heutzutage immer mehr IT-System in die Prozesse, die sie unterstützen integriert werden, entstehen auch immer mehr Daten. Die Unternehmen haben aber Probleme, mit dieser Menge an Daten umzugehen und einen tatsächlich Wert daraus zu ziehen. Hier kommt Process-Mining ins Spiel, das mithilfe der folgenden drei Phasen die Daten praktisch verwertet. Im Gegensatz zu normalem Prozess Management liegt der Fokus nicht nur auf dem Modellieren der Prozesse, sondern in der Nutzung der Daten.
Die 3 Phasen im Process Mining
Prozesserkennung | process discovery:
Auf Basis der gegebenen Daten wird ein Modell erstellt, das das tatsächliche Modell eines Prozesses widerspiegelt. Anfangs ging das nur mit sequentiellen Modellen, wobei mit dem Alpha Algorithmus als ersten Algorithmus das Problem der Nebenläufigkeit gelöst wurde (s. Kapitel Algorithmen).
Konformitätsprüfung | conformance checking:
Man versucht Unterschiede zwischen Prozess-Modell und tatsächlichem Ablauf des Prozesses zu finden. Ein existierendes Prozess Modell, sei es durch Process Discovery, oder manuell erstellt, wird also mit Event Logs des gleichen Prozesses verglichen. Gibt es zum Beispiel Regeln, an die sich in einem Prozess gehalten werden muss, kann gecheckt werden, ob das auch tatsächlich der Fall ist. Hier kann auch festgestellt werden, ob das Modell noch verbessert werden muss. Es werden also Abweichungen erkannt, lokalisiert und erklärt.
Prozessverbesserung | process enhancement:
Hier ist das Ziel, ein bereits existierendes Modell zu erweitern oder zu verbessern, anhand von Informationen, die bereits über einen Prozess gesammelt wurden.
Verbessern: Eine Art davon wäre das Reparieren eines Prozess Modells, das heißt, dass das Modell so angepasst wird, dass es die Realität besser widerspiegelt. Beispielsweise, wenn zwei Aktionen hintereinander im Modell dargestellt werden, in Realität aber in beliebiger Order geschehen können. Auf diese Weise wird die Fitness des Modells gesteigert.
Erweitern: Eine andere Art wäre eine Erweiterung des Prozess Modells. Man kann beispielweise mit neuen Daten, neue Ansichten auf ein Modell erstellen. Mit Performance Daten in Form von Zeitstempeln zum Beispiel können dann Engpässe identifiziert oder Durchlauf-Zeiten analysiert werden.
Simulationen: Try-and-error, ohne dass die Konsequenzen der Fehler tatsächlich getragen werden müssen. Das ist zum Beispiel sehr praktisch, wenn entschieden werden soll, worauf die Prioritäten gesetzt werden und wie limitierte Ressourcen benutzt werden sollen.

Diese drei Phasen von Process Mining sind in der realen Welt zyklisch (s. Abb. 1) Die Real-Welt wird von IT-Systemen unterstützt und kontrolliert wird. Durch Einbindung der IT-System in der Real-Welt werden die Event Daten gewonnen. Anhand derer wird schließlich das Prozess Modell erstellt, das wiederum direkt Einfluss auf die IT-Systeme hat. Conformance checking steht zwischen dem Prozess Modell und den Event Daten und gleicht ständig ab. Auf Basis des Prozess Modells und der Event Daten läuft Process Enhancement, welches das Prozess Modell und darüber auch die Real-Welt beeinflusst.
Mithilfe der datenbasierten Einsichten, kann ein Unternehmen Verbesserungen schnell übernehmen und auch Automatisierungsmöglichkeiten für repetitive Aufgaben können gefunden werden.
Perspektiven
Man muss auch außerdem beachten, dass es für diese Modelle auch unterschiedliche Perspektiven gibt:
- Kontrollfluss-Perspektive: Hier handelt es sich um die Anordnungen der Aktivitäten, die durchgeführt werden. Alle möglichen Pfade, die in einem Prozess ablaufen können, werden hier festgehalten. Für andere Perspektiven gibt es andere Notationen, in die umgeschrieben werden kann.
- Organisationaufbau-Perspektive: Hier werden die Modelle mit Informationen über Ressourcen, wie Personen, die involviert sind angereichert. Ein Unternehmen kann soziale Netzwerke zwischen den Personen aufstellen, verschieden Mitarbeiter gruppieren und sogar einzelne Personen analysieren. Bei dieser Perspektive muss allerdings stark auf Datenschutz geachtet werden.
- Case-Perspektive: Ein Case repräsentiert einen kompletten Durchlauf in einem Prozess Modell (s. Kapitel Event Daten). Hier können die Attribute von den Cases betrachtet werden. Man würde dabei beispielsweise sehen, wenn es Zusammenhänge zwischen Störungen und Lieferanten gibt.
- Performance-Perspektive: Diese Perspektive befasst sich mit allem, das mit Zeitstempeln zu tun hat. Es geht dabei oft um das Finden von Engpässen oder das Berechnen von Durchlauf Zeiten.
Generell können diese unterschiedlichen Perspektiven aber natürlich auch überlappend sein.
Möglichkeiten und Vorteile bei Process Mining
Nachteile bei einem manuell erstellten Prozess Modell: - Designer konzentriert sich nur auf normales und gewünschtes Verhalten, obwohl das meist nur 80% der Fälle abdeckt. Die Anderen 20% verursachen aber üblicherweise 80% der Fehler. - Modell wird oft davon beeinflusst, welche Rolle der Designer im Unternehmen spielt - Es mag bei einem Bandarbeiter, der den ganzen Tag das gleiche macht, vielleicht leicht sein, den Prozess darzustellen, aber sobald Menschen, die in verschiedenen Prozessen gleichzeitig arbeiten, betrachtet werden, wird es schwieriger. Es ist unmöglich einen Prozess in Isolation zu betrachten, wenn die Mitarbeiten ihre Aufmerksamkeit aufteilen müssen und unterschiedlichste Prioritäten haben. - Das Abstraktionslevel festzulegen ist sehr schwierig und sobald man sich auf ein Abstraktionslevel festgelegt hat, ist es extrem aufwändig, das wieder zu ändern. Außerdem ändern sich die Abstraktionslevel mit der Zeit meistens. - Modell stellt oft eher die idealisierte Version eines Prozess Modells dar und nicht die tatsächliche.
Deshalb wird Process Mining benötigt, hier wird auf Basis von vorhandenen tatsächlichen Daten mit dem Bottom-up Prinzip das Prozess Modell konstruiert. Auf diese Weise wird nicht der Soll-, sondern der Ist Prozess dargestellt und man bekommt einen objektiven Einblick in die Prozessstruktur.
Außerdem gibt es dadurch nicht nur ein Modell, sondern unterschiedliche Modelle auf Basis derselben Fakten. Der Benutzer kann entscheiden, welches Abstraktionslevel er gerne sehen möchte. Ein weiterer Punkt ist, dass das Modell den Mitarbeiter mit all seinen Facetten sieht, die ineffizienten Tätigkeiten, aber auch, wenn einzelne Personen flexibel mit Problemen und mit sich verändernden Workloads umgehen.
Event Logs

In der Abbildung 2 sieht man einen sogenannten Event Log. Jede Zeile repräsentiert ein Event, jedes Event hat eine eindeutige ID, die Events sind gruppiert in einzelne Cases, die die einzelnen Prozessabläufe repräsentieren.
Außerdem haben die Events noch beliebig viele Attribute, wie beispielsweise den Zeitstempel. Diese Attribute können beliebig detailliert festgehalten werden und in jeglichen Bereich gehen, wie beispielsweise Ressourcen oder Kosten. Es müssen auch nicht alle Events die gleichen Attribute haben, wobei es typisch ist, dass Events, die die gleiche Aktivität repräsentieren, den gleichen Satz an Attributen haben.
Wichtig ist jedoch: um für Process-Mining nutzbar zu sein muss ein Event zu einem Case und zu einer Aktivität zugeordnet sein. Das ist das Minimum. Außerdem müssen die Events innerhalb eines Case geordnet sein. Ohne die Information, in welcher Reihenfolge die Events abliefen, ist es unmöglich Abhängigkeiten herauszufinden.
Um allerdings schließlich mehr Informationen zu bekommen, beispielweise in Richtung Performance, braucht es Attribute, wie den Zeitstempel.
Petri-Netz
Petri-Netze können eine visuelle Repräsentation für ein Prozess-Modell sein. Es gibt wie oben beschrieben unterschiedliche Perspektiven aus denen man ein Prozess-Modell analysieren kann, weshalb es auch unterschiedliche Darstellungsformen gibt.
Um es einfacher zu halten, wird ein Beispiel in der Kontrollflussperspektive gegeben und nicht auf alle einzelnen Perspektiven eingegangen.
Warum Petri-Netze
Petri-Netz ist die älteste und am besten erforschte Modellierungssprache, die das Modellieren von Nebenläufigkeit erlaubt. Im Gegensatz zu einfacheren Darstellungsformen, lassen sich hier parallele Aktivitäten gut darstellen. Die grafische Notation ist intuitiv und simple und trotzdem sind die Netze ausführbar und mit bestimmten Techniken analysierbar. Für die unterschiedlichen Perspektiven und Nutzungsarten gibt es aber bereits erweiterte Petri Nets, die auch den Daten und Zeit Bezug mit abbilden können.

Das Petri Netz in der Abbildung 3 beschreibt die Abfertigung einer Anfrage für Entschädigung in einer Airline. Man kann einen Start und ein Ende sehen. Es gibt außerdem Übergänge, die mit Quadraten gekennzeichnet sind und Orte, die mit einem Kreis gekennzeichnet sind. Diese Orte repräsentieren die Zustände in denen sich das System befinden kann. Die Übergänge sind durch die Orte verbunden. Das Netz an sich ist statisch, allerdings gibt es zusätzliche Tokens, die gefeuert werden, in Form von Punkten, wie hier in Start. Der Zustand des Netzes wird durch die Verteilung ebendieser Tokens über die verschiedenen Orte beschrieben und diese Verteilung wird als "Marking" bezeichnet. In dem Netz das Sie jetzt sehen, ist nur der Ort "Start" markiert.
Funktion Petri-Netz
In einem Petri Netz ist ein Übergang freigegeben, das heißt die dazugehörige Aktivität kann geschehen, wenn alle Eingabe-Orte einen Token haben, also markiert sind. In dem Beispiel aus der Abbildung hat "register request" nur einen Eingabe-Ort und dieser Ort ist markiert. Das heißt "register request" kann durchgeführt werden. Wenn "register request" durchgeführt wird, versteh man das als Feuern. Der Übergang nimmt von jedem Eingabe-Ort einen Token auf und feuert dann an jeden Ausgabe-Ort einen Token ab. Hier konsumiert "register request" also einen Token und produziert zwei neue Tokens für c1 und c2. Nun sind drei neue Übergänge freigegeben: "examine throughly", "examine casually" und "check ticket". Es kann nun entweder "examine throughly" oder "examine casually" durchgeführt werden, da es nur einen Token gibt. Wenn einer von den zwei Übergängen durchgeführt wird, wird der Token von c1 konsumiert und der andere Übergang ist nicht mehr freigegeben. "check ticket" hat jedoch einen eigenen Eingabe-Ort mit einem eigenen Token. Das heißt dieser Übergang kann parallel durchgeführt werden. Oben wird dann entweder "examine throughly" oder "examine carefully" durchgeführt, wodurch der Token in c1 konsumiert wird und ein Token zu c3 gefeuert wird und unten konsumiert und feuert "check ticket", sodass nun Token bei c3 und c4 sind. Dadurch wird "decide" freigegeben, da alle Eingabe-Orte von dem Übergang "decide" einen Token haben. Auf diese Weise kann das Netz weiter ausgeführt werden. Ein solches Netz kann auch zyklisch sein, wie sich an "reinitiate request" erkennen lässt.
Der Prozess endet nachdem entweder die Entschädigung gezahlt wurde, oder die Anfrage zurückgewiesen wurde. In einem Petri Netz können auch gleichzeitig mehrere Tokens an den unterschiedlichen Orten sein, die dann unterschiedliche Cases aus dem Event Log repräsentieren.
Mithilfe dieses Token basierten Ansatzes, kann auch conformance checking sehr einfach durchgeführt werden. Vor allem zu Beginn von Process Mining, war das sehr verbreitet. Inzwischen gibt es aber auch schon neue Ansätze, die noch besser funktionieren., oft aber trotzdem auf ähnlichen Prinzipien basieren.
Algorithmen für Process Mining
Es gibt jede Menge Algorithmen, die innerhalb des Process Mining genutzt werden, insbesondere auch, um das Prozess Modell zu erstellen.
Übersicht Algorithmen und Herausforderungen
Die ersten drei Process Miner überhaupt waren allesamt basierend auf Rückgekoppelten Neuronalen Netzen.
Dann wurde der Alpha Miner entwickelt, der Arbeitsflussmodelle konstruieren konnte und automatisch Petri Netze erstellt, die dann weiter analysiert werden konnten.
Generell gibt es relativ viele Probleme mit denen die Algorithmen klarkommen müssen. Die Algorithmen werden auch heute immer noch auf Basis dieser Probleme weiterentwickelt:
- Die Korrelation finden: Teilweise ist es schwierig zu Events die zugehörigen Cases zu finden. Die Korrelation zwischen Case und Event kann also zum Problem werden.
- Timestamps: die Events müssen in einer Reihenfolge geordnet sein, natürlich braucht es eigentlich keine Timestamps, aber um diese Ordnung innerhalb der Cases herauszufinden in vielen Fällen schon. Timestamps sind aber oft fehlerhaft, sei es wegen falschen Zeiten im System, oder einfach, weil der Abschluss nicht direkt aufgezeichnet wird, wenn ein Event erfolgt ist. Ein Problem kann auch sein, dass nur der Tag des Eventabschlusses angegeben wird, an diesem Tag aber mehrere Events stattgefunden haben.
- Umfang: Zu determinieren, wie groß der Umfang sein soll ist schwierig und hierfür wird häufig Expertenwissen benötigt. In vielen Unternehmen gibt es Unmengen an Daten und es ist unklar, welche Daten überhaupt benötigt werden.
- Granularität: Es ist schwierig zu sagen, wie genau die Event Logs sein müssen, es kann sein, dass es Unmengen an Informationen zu einzelnen Events gibt, das Ziel aber nur eine Übersicht des Arbeitsablaufs ist, das dem Stakeholder präsentiert werden soll.
- Und ein großer Punkt ist auch noch die Datenqualität bei falschem Logging:
- Missing in log: Etwas ist in der Realität passiert, wurde aber nicht aufgezeichnet
- Missing in reality: Ein Event wurde aufgezeichnet, ist aber in der Realität gar nicht passiert
- missing attribute: Ein Attribut eines Events fehlt
- Incorrect attribute: Ein Attribut eines Events ist falsch aufgezeichnet
- Imprecise attribute: Das Attribut eines Events wurde zu ungenau aufgezeichnet
- Noise: Der Algorithmus muss mit Noise umgehen können. Für den Algorithmus ist es eigentlich unmöglich zwischen besonderen Events und falschem Logging zu unterscheiden, hier braucht es oft menschliche Beurteilung.
- Vollständigkeit: Ein weiterer Grund wären zu wenig Daten, um daraus ein repräsentatives Modell zu erstellen ⇒ Es kann also bei Noise zu viele Daten geben oder bei der Vollständigkeit zu wenige Daten geben. Es ist schwierig zu sagen, ob man alle möglichen Abläufe schon in den Trainingsdaten gesehen hat oder vielleicht ein Trace eigentlich möglich aber bisher einfach noch nicht aufgetreten ist.
Die Probleme in Datenqualität kommen oft daher, dass Event Daten oft einfach nur als Nebenprodukt gesehen werden und deshalb kein großer Wert auf die Qualität gelegt wird
Alpha Algorithmus
Da der Alpha Miner der erste Prozesserkennungs-Algorithmus war, der Nebenläufigkeit von Events verarbeiten konnte und viele der darauffolgenden Algorithmen auf Basis dessen entstanden sind, wird im Folgenden genauer darauf eingegangen.
Der Alpha Miner verarbeitet Event Logs und erstellt darauf basierend ein Petri Netz, das die Logs widerspiegelt.
Dafür basiert der Alpha Miner auf 3 Regeln:
- Temporal dependency: b folgt a aber a folgt niemals b ⇒ b ist abhängig von a; geschrieben a → b

- Temporal independency: es gibt Aufzeichnungen bei denen a auf b folgt, aber auch welche, bei denen b auf a folgt ⇒ a und b können parallel durchgeführt werden; geschrieben a || b

- Independency: Es gibt keine Aufzeichnung bei der a auf b folgt oder b auf a folgt ⇒ die beiden Events sind unabhängig voneinander; geschrieben a # b
Ablauf Algorithmus

Dann wird der Algorithmus wie in Abbildung 6 zu sehen durchgeführt. Für ein besseres Verständnis direkt an einem Beispiellog L.
L = [

- ({a},{b}), ({a},{c}), ({a},{e}), ({b},{d}), ({e},{d}), ({c},{d}) unabhängig von sich selbst aber „temporal dependency“ zwischen A und B
- ({a},{b,e}), ({a},{c,e}), ({b,e},{d}), ({c,e},{d}) “temporal dependency” zwischen allen Events in A und allen Events in B, die Events in A sind alle unabhängig voneinander und die Events in B sind unabhängig voneinander
5. Alle Non-Maximum Sets werden gelöscht => unnötige Duplikate löschen
- ({a},{b}) ist beispielsweise bereits in ({a},{b,e}) repräsentiert und kann deswegen gelöscht werden. Das Gleiche gilt für mehrere Sets weshalb folgende Sets übrigbleiben:
({a},{b,e}), ({a},{c,e}), ({b,e},{d}), ({c,e},{d})
6. Es werden Orte für alle Sets erstellt und ein Start- und Endpunkt festgelegt
7. Verbindungen werden aufgezeichnet …
8. …und das Petri Netz wird zurückgegeben

Daten für Process Mining
Abbildung 9
Natürlich braucht man für Process Mining als Erstes die Daten, also ist es wichtig zu verstehen, wie man zu den Daten kommt.
Die Anforderungen an die Daten kommen auf die Process Mining Technik an, die verwendet werden soll, damit auch das Ziel, das verfolgt wird ⇒ Welche Frage soll beantwortet werden mit dem Modell? Welche Sichtweisen sind essentiell bei den vorhandenen Daten? Natürlich muss außerdem mit Qualitäts Problemen in den Daten umgegangen werden.
Die Sichtweise ist für das Auswählen der Daten sehr entscheidend. Schaut man sich beispielsweise ein Krankenhaus an, sind die manche daran interessiert, welche Schritte der Patient während des Krankenhausbesuches durchläuft und andere daran, wie man den Arbeitsablauf innerhalb einer bestimmten Abteilung verbessern kann.
Es kann erst einmal eine Vielzahl an Datenquellen geben, seien es Datenbanken, Nachrichtenprotokolle, Transaktionsprotokolle oder ERP-Systeme. Schließlich wird im Zusammenhang mit Data Mining oft von ETL = extract, transform and load geredet. Wobei man bei transform vor allem auf Syntax und Semantik achten muss. Dadurch werden die gesammelten Daten verarbeitet in ein Zielsystem geladen.
Teilweise gibt es schon ein Data Warehouse, teilweise noch nicht. Die Daten müssen in jedem Fall extrahiert werden und in Event Logs umgewandelt werden. Wie in Event Logs schon betrachtet braucht es dafür eine Reihenfolge innerhalb der Cases, einen Namen für die Aktivität der Events und die dazugehörige Case.
Dann werden die unterschiedlichen Techniken process discovery, conformance checking und process enhancement angewendet.
Allerdings ist das ganze iterativ. Sobald ein Prozess Modell erstellt wurde kommen höchstwahrscheinlich neue Fragen auf, wofür neue Daten gesammelt werden müssen und so läuft der Prozess immer wieder durch. Wie auch schon bei den Algorithmen besprochen gibt bei den Daten einige Herausforderungen, neben dem Expertenwissen, dass man in Bezug auf Datenschutz und Datenqualität bezüglich Inhalt braucht, muss auch auf Noise, falsches Logging und die Vollständigkeit der Daten geachtet werden.
Qualitätsmessung
Meistens wird die Qualität anhand folgender vier Kriterien bestimmt.
Fitness: Ein Modell ist hier perfekt, wenn alle Abläufe aus dem Log von Anfang bis Ende durchlaufen können.
Einfachheit: Das einfachste Modell, das das Verhalten aus dem log widerspiegeln kann, ist das beste Modell. Man versucht also ein Modell zu erstellen, das das Verhalten mit möglichst wenigen Informationen widerspiegeln kann.
Präzision: Ein Modell ist präzise wenn es nicht zu viel Verhalten erlaubt. Ein Modell, das nicht präzise ist underfitted. Schlechte Präzision würde Verhalten erlauben, das nicht im Event Log repräsentiert war.
Generalisierung: Ein Modell sollte generalisieren und sich nicht genau auf die Beispiele im Event Log begrenzen. Ein Modell, dass nicht generalisiert overfitted. Bei wenig Generalisierung würde das Modell nur genau das Verhalten aus dem Log repräsentieren.
Anwendungen
Anhand der Menge der Paper, die zu den einzelnen Themen veröffentlicht wurden, kristallisieren sich einige Anwendungsgebiete heraus, die besonders vertreten sind:
- Das Gesundheitswesen mit beispielsweise klinischen Pfaden, Patientenbehandlungen, oder der Analyse der primären Prozesse eines Krankenhauses. Ein exaktes Beispiel wäre die Analyse der Chancen einer bestimmten Behandlung oder Korrelationen zwischen verschiedenen angewandten Behandlungen. Eine Quelle sagt sogar, dass Process Mining eine von den Anwendungen ist, die die größten Vorteile aus den vorhandenen Daten im Gesundheitswesen ziehen kann.
- Informations- und Kommunikationstechnologien: bei Software Developement, in IT-Betriebsdienstleistungen und Telekommunikationsunternehmen, wenn zum Beispiel Engpässe identifiziert werden sollen.
- In der Fertigung: Bei industriellen Aktivitäten, die von Fabriken durchgeführt werden und Produkte liefern, v.a. vertreten im Automobilsegment
- In der Bildung: Beim E-Learning, bei wissenschaftliche Anwendungen und in Forschungszentren mit Innovationsprozessmanagement. Zum Beispiel beim Entwickeln produktiver Lernpfade, basierend auf bestimmten Nutzergruppen.
- In den Finanzen: in Prozessen wie Bezahlung, Investitionen, Einlagen oder bei Risikoanalyse und -minderung
- In der Logistik: Bei Transport, Lagerung und Bestandsmanagement
Trends – KI

Process Mining allein hat nichts mit Künstlicher Intelligenz zu tun, denn KI ist für die angestrebten Resultate – Transparenz, Auswertungen zur Prozessleistung und Identifikation von Abweichungen – eigentlich nicht notwendig.
Im Bereich der analytischen Methodik unterscheidet man vier aufeinander aufbauenden Ebenen (s. Abb. 9). In der deskriptiven Analytik ist Process Mining alleine aktiv, aber für die darauffolgenden Ebenen hat der Einsatz von KI großes Potential. Um zu erklären, warum etwas passiert ist ⇒ diagnostisch; was passieren wird, also Vorhersagen ⇒ Prädiktive Analytik; Und schlussendlich sogar um Handlungsempfehlungen auszusprechen, also wie muss gehandelt werden, damit ein zukünftiges Ereignis eintritt oder eben nicht eintritt ⇒ Präskriptive Analytik.
Anhand der identifizierten Problemursachen können Entscheider gezielte und effektive Verbesserungsmaßnahmen umsetzen. Künstliche Intelligenz ist also kein zwingend notwendiges Kriterium, kann aber das Potential vergrößern. KI wird also zunehmend eingesetzt um die Potentiale der Process Mining Anwendungen zu erweitern. KI wird zum Beispiel integriert, um einzelne Teilbereiche und Arbeitsschritte des Process Mining zu unterstützen und bessere Ergebnisse zu erzielen.
Ein Beispiel wäre eine auf KI basierte Technologie, die in der Lage ist Arbeitsabläufe zu verstehen und daraus folgend Schlussfolgerungen abzuleiten. Auf diese Weise erweitern die Anwendungen der KI das klassische Process Mining von einem explorativen Ansatz hin zu zunehmend intelligenter und vollständig automatisierter Prozessanalyse. Der entscheidende Unterschied zum klassischen Process Mining besteht darin, dass sich das System kontinuierlich mithilfe von KI automatisch optimiert und sich den ständig ändernden Rahmenbedingungen anpasst.
Ein anderes Beispiel wäre Maschinelles Lernen zur Verbesserung der Datenqualität, sowie zur Gruppierung und Strukturierung der Daten. Es würde also im Bereich transform von ETL eingesetzt werden, den wir zuvor schon bei dem Sammeln der Daten gesehen haben. KI hilft also mit den ganzen Problemen umzugehen, die in dem Kapitel Algorithmen ausführlich angesprochen wurden. Da die Qualität der Daten sehr ausschlaggebend für das Endergebnis ist, würde eine Verbesserung der Daten die Qualität des Prozess Modells sehr steigern.
Maschinelles Lernen kann hierbei auch eingesetzt werden, um die Dateneingabe zu automatisieren, Duplikate zu erkennen und zu entfernen und um unstrukturierte Daten in Formate umzuwandeln, die von Process-Mining Anwendungen gelesen werden können.
Code Demo Process Mining
von Quirin Joshua Groszeibl
import os
import pandas as pd
import networkx as nx
import matplotlib.pyplot as plt
Daten laden
Zuerst brauchen wir Daten, die wir verwerten können. In diesem Fall laden wir dazu eine CSV-Datei hoch. Das Beispiel hierbei ist ein Datensatz von Kaggle mit über 27k Reihen Eventlogs einer Autoversicherungsfirma, diese begrenzen wir für diese Demo auf 200 Reihen, damit das Kompilieren nicht allzu lange dauert.
# Load the event log as a DataFrame
event_log = pd.read_csv('/home/qsh1ne/CODE_DEMO_SEM_KI_23/Insurance_claims_event_log.csv',
nrows=200, usecols=['case_id', 'activity_name', 'timestamp'])
Process Discovery - Daten verstehen
Damit wir eine Fehlerfreie Analyse durchführen können, benötigen wir zuerst ein Verständnis für unsere Daten. Eine Frequenzanalyse hilft uns direkte Zusammenhänge zwischen den Variablen besser zu verstehen. Für die spätere Visualisierung erstellen wir anschließend einen gerichteten Graph, dessen Knoten wir mit den Subprozessen der Case ID bestücken.
# Perform frequency analysis to get the directly-follows relations
dfg = event_log.groupby(['case_id', event_log['activity_name'].shift(-1)]).size().reset_index(name='count')
# Create a directed graph
graph = nx.DiGraph()
# Add nodes and edges to the graph
for _, row in dfg.iterrows():
graph.add_edge(row['activity_name'], row['activity_name'], weight=row['count'])
# Visualize the graph
pos = nx.spring_layout(graph, seed=42)
labels = nx.get_edge_attributes(graph, 'weight')
weights = [graph[u][v]['weight'] / 10 for u, v in graph.edges()]
nx.draw_networkx(graph, pos, with_labels=True, node_size=500, node_color='lightblue',
edge_color='gray', width=weights, font_size=8)
nx.draw_networkx_edge_labels(graph, pos, edge_labels=labels, font_size=6)
Anschließend lassen wir uns den Graphen als Bild ausgeben.
# Save the process graph as an image file
output_dir = '/home/qsh1ne/PM_Code_Demo/output'
os.makedirs(output_dir, exist_ok=True)
process_graph_file = os.path.join(output_dir, 'process_graph.png')
plt.savefig(process_graph_file)
print(f"Process graph saved as {process_graph_file}")
Conformance Checking - Prozess Spektrum errechnen
Das Errechnen des Prozess Spektrums ganz einfach über das Zählen der einzelnen Aktivitäten in der Anzahl. Jeder Subprozess muss einen sehr ähnlichen Ablauf haben, um mit dem PSM gute Vorhersagen treffen zu können. Beispielsweise eignen sich Maschinendaten oder Bürokratische Abläufe sehr gut, während Daten von Sportwettkämpfen hierbei weniger gute Ergebnisse liefern.
Es gilt: Je ähnlicher die Prozesse, desto einfach die Auswertung.
Auch hier visualisieren wir die Ergebnisse zuerst und speichern diese anschließend als Bild ab.
# Calculate process spectrum
spectrum = event_log['activity_name'].value_counts().sort_values(ascending=False)
# Plot the process spectrum
plt.figure()
spectrum.plot(kind='bar', color='lightblue')
plt.xlabel('Activity')
plt.ylabel('Frequency')
plt.title('Process Spectrum')
# Save the process spectrum plot as an image file
spectrum_plot_file = os.path.join(output_dir, 'process_spectrum.png')
plt.savefig(spectrum_plot_file)
print(f"Process spectrum saved as {spectrum_plot_file}")
Beispiel: Hierbei fällt auch schon der erste Fehler auf, die ersten 200 Reihen anstelle der gesamten 27k Reihen, verfälscht in diesen Fall aus 2 Gründen die Ergebnisse. Zum einen ist 200%6 =! 0, dementsprechend fehlen Subprozesse des letzten eigentlichen Prozesses, aber auch betrachten wir weniger als 0,007% der Datenmenge. So können unmöglich schlagkräftige Ergebnisse erzielt werden, aber für den Zweck dieser kleinen Demonstration ist es genügend.
Process Enchancement - Performance Spektrum errechnen
Die ersten komplexeren Berechnungen nimmt uns hierbei die Pandas Libary ab, in dem diese die Eventlogs in zuerst in eine einheitliches und auswertbares Zeitformat umformt. Wir setzen die Startzeiten auf die geringste Dauer, und die Endzeiten auf die höchste der jeweiligen Cases. Anschließend subtrahieren wir Startzeit von der Endzeit, und uns bleibt eine durchschnittliche Zeit für die Dauer der jeweiligen Aktivitäten.
Anschließend visualisieren wir unsere Ergebnisse wieder, und geben diese als Bild aus.
# Calculate case durations
event_log['timestamp'] = pd.to_datetime(event_log['timestamp'])
start_times = event_log.groupby('case_id')['timestamp'].min()
end_times = event_log.groupby('case_id')['timestamp'].max()
case_durations = end_times - start_times
# Plot the performance spectrum
plt.figure()
case_durations.dt.total_seconds().plot(kind='bar', color='lightblue')
plt.xlabel('Case ID')
plt.ylabel('Duration (seconds)')
plt.title('Performance Spectrum')
# Save the performance spectrum plot as an image file
performance_spectrum_file = os.path.join(output_dir, 'performance_spectrum.png')
plt.savefig(performance_spectrum_file)
print(f"Performance spectrum saved as {performance_spectrum_file}")
Neben den hier verwendeten Libarys sind folgende erwähnenswert, allerdings dauert die Implementation wesentlich länger und diese Demo ist zeitlich sehr beschränkt.
- pm4py
- pmi
ProM 6.9

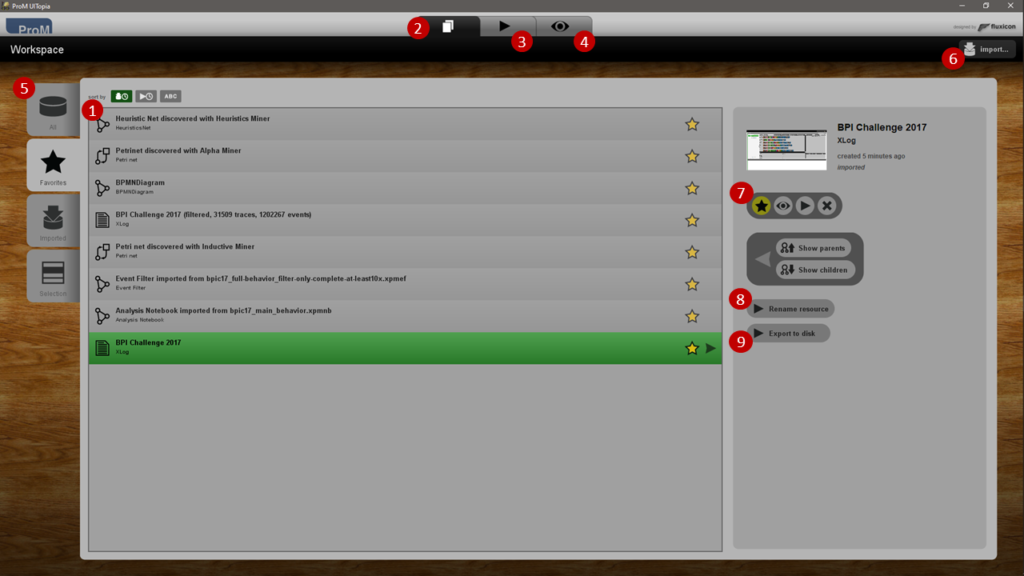
Die ProM Plattform ist ein plugin-basierendes Framework speziell für Process Mining. Zentriert auf drei Basiskonzepten.
- Data Objects (1) im Workspace Tab (2)
- Plugins (3)
- Visualisierung (4)

Workspace
Ansicht (5) von allen Objekten, den Favorisierten Objekten und Importierten Objekten.
Objekte importierbar über den Import Button (6) oder via drag&drop.
Im Workspace kann außerdem: - (7) favorisiert (Stern), angeschaut (Auge), Plugin gestartet (Play) oder gelöscht (Kreuz), - (8) umbenannt, - (9) exportiert werden.
Praktische Anwendung
Die Code Demo ist ein wenig kurz an tatsächlichen Code gekommen, aber mir war es wichtiger einen sinnvollen Einblick in die praktische Arbeit mit Prozess Mining zu geben.
Fangen wir nun mit der Umwandlung der CSV-Datei an. Zuallererst schauen wir uns dazu wie vorab beschrieben den Inhalt an für ein Verständnis der Daten, und klassifizieren die Eingabevariablen.

Umwandlung in XES-Format
Anschließend übertrage wir die Variabel Klassifizierung und alle Spalten und Reihen der CSV-Datei in ein XES Format, dies machen wir mit dem zugehörigen Standard-Plugin von ProM 6.9.

Analyse
Die XES-Datei können wir problemlos in das Performance Spektrum Plugin einfüttern.

Das Feintuning der Parameter und das Setzen eines eigenen Classifier ist optimal, kann aber je nach dem Ziel des Anwenders stark die Ergebnisse berichtigen und verfälschen. Die ersten zwei Ausgabebilder werten die Versicherungsdaten in Quantilen aus:


hier die mediale Auswertung:


Auswertung
Zur Auswertung nehme ich den medialen Ansatz her, da er hierbei mehr Sinn ergibt. Man kann deutlich erkennen bei der 2. Abbildung, dass die ersten Prozesse die erste Benachrichtigung über den Verlust sind, und die letzte das Abschließen durch abgeschlossene Bezahlung oder durch Entscheidung keine Zahlung zu senden ist. Ebenfalls zu sehen ist, dass die meisten sehr (Dunkelblau) und langsamen (Orange) sich innerhalb sehr spezieller Prozesse befinden, während die häufigsten Prozesse (First Notification) schon sehr gut optimiert sind und komplett normal im Durschnitt ablaufen. In der ersten Abbildung ist ebenfalls zu sehen, wie verschiedene Prozesse sich überschneiden. Die Linien stellen jeweils einen Prozess von Beginn bis Ende da. Dies ist bei den oft vorkommenden Prozessen leider sehr unübersichtlich, während es bei den weniger Häufigen Prozessen zu wesentlich besser sichtbaren Resultaten führt.
Verwendeter Datensatz
- https://www.kaggle.com/datasets/carlosalvite/car-insurance-claims-event-log-for-process-mining?resource=download
Ergebnisse Berechnungen via Python Code



Weiterführendes Material
Podcast
Hier Link zum Podcast.
Talk
Hier einfach Youtube oder THD System embedden.
Demo
- https://github.com/qsh1ne/CODE_DEMO_SEM_KI_23
Literaturverzeichnis
- van der Aalst, Wil (2016): Process Mining - Data Science in Action, 2.Aufl., Berlin, Deutschland: Springer
- Macak, Martin/Daubner, Lukas/Fani Sani, Mohammadreza/Buhnova, Barbora (2022): Process mining usage in cybersecurity and software reliability analysis: A systematic literature review, in: Array, Volume 13
- dos Santos Garcia, Cleiton/ Meincheim, Alex/Ribeiro Faria Junior, Elio/ Rosano Dallagassa, Marcelo/Maria Vecino Sato, Denise/ Ribeiro Carvalho, Deborah/ Alves Portela Santos, Eduardo/Emilio Scalabrin/Edson (2019): Process mining techniques and applications - A systematic mapping study, in: Expert Systems with Applications, Volume 133, S. 260-295
- IBM Technology (2023): What is Process Mining? [YoutTube], https://www.youtube.com/watch?v=5thuFbUQ7Qg
- Study Conquest (2018): Alpha Algorithm (Process Discovery Method)[YouTube], https://www.youtube.com/watch?v=nOTehxTiFFU
- Dager, Shirin (2020): Process Mining hat nichts mit KI zu tun! Erstmal..., der-prozessmanager, [online] https://der-prozessmanager.de/aktuell/news/zusammenhang-von-process-mining-und-ki [abgerufen am 27.05.2023]
- Zaharia, Silvia, Korth, Alexander (2022): Datennutzung im E-Commerce, in: Marketing Analytics, S. 215-228
- Barenkamp, Marco (2022): Künstliche Intelligenz als Unterstützungsfunktion der Vorhersage und Prozessexzellenz im Process Mining, in: Wirtschaftsinformatik&Management, Nr. 14, S. 160-170